- 欢迎来到 浩特工业!
- 010-5957 6240 028-8331 1885
- william.lai@hot-mining.com | kira.zhang@hot-mining.com
-




选矿(选煤)的人工智能应用如何选择最佳机器学习算法?
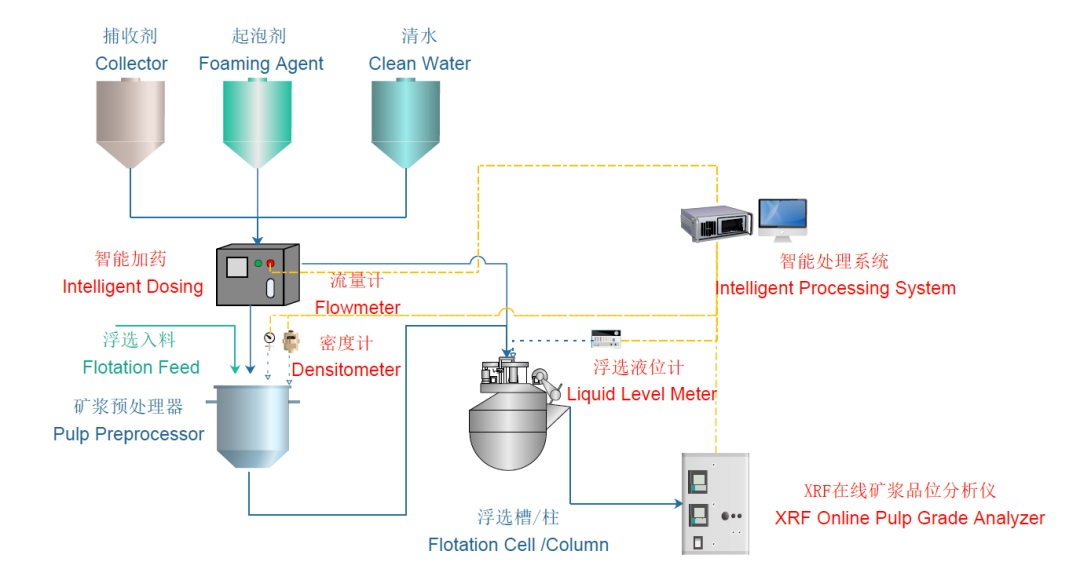
谁是浩特?请参考下图

作者:大爷(HOT)

第一步是确定想要解决的问题:要解决的问题是降维、预测、分类还是聚类问题?这可以缩小选择范围,并决定选择哪种类型的算法。
你想解决什么类型的问题?
分类问题:逻辑回归、决策树分类器、随机森林分类器、支持向量机(SVM)、朴素贝叶斯或神经网络。
主要应用:矿物预分拣(比如:XRT)、矿物品位及元素检测(XRF-X射线荧光矿浆品位检测、X射线灰分仪)、智能浮选、预测性维护等。
聚类问题: k-means聚类、层次聚类或DBSCAN。
主要应用:在建立有监督机器学习算法进行分类和预测应用之前,需要对大量原始数据进行非监督的机器学习,实现对数据的聚类分析,找到不同类别数据之间的关系和隐藏特征。
比如:在选煤厂智能密控系统建立模型前,需要找到各个数据之间的关系(各类阀门开度与分选密度的关系,阀门开度之间的关系等)。重介质选煤工艺中最重要的三个变量是重质悬浮液的密度、煤泥含量和合格介质桶液位。HOT对重介质选煤控制过程中数据反馈、参数设置、重介质密度控制的研究,建立预测重介质悬浮液密度的模型。在此过程中,HOT利用最小二乘支持向量(LS-SVM)算法对样本数据进行了训练,建立灰色测量仪校正模型,可以对在线灰色测量仪中检测到的数据进行及时校正。
a)数据集的大小
如果数据集很小,就要选择一个不那么复杂的模型,比如线性回归(对于100个样本以内的数据分析,Excel就能很好的实现对多个变量包括二进制变量的线性回归分析)。对于更大的数据集,更复杂的模型,如随机森林或深度学习可能是合适的。
数据集的大小怎么判断:
大型数据集(数千到数百万行):梯度提升、支持向量机、神经网络或深度学习算法。
小数据集(小于1000行):逻辑回归、随机森林、决策树或朴素贝叶斯。
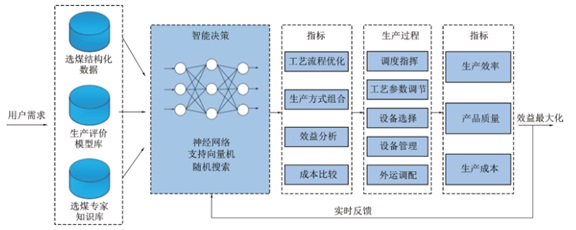
对于选矿厂和选煤厂来说,数据量通常都非常大,比如:智能密度控制系统,仅几个班组的灰分、密度、阀门开度等数据量就多达几千行,这还仅仅是整个选煤工艺的一个生产环节。尤其是拥有多个选矿厂和选煤厂的大中型矿业集团公司,对海量数据的清洗、分析、应用等工作是非常有挑战的。比如:神东煤炭集团上湾智能化选煤厂建立了定制精准生产开发与应用模型(如下图),与神东ERP、业务执行系统数据对接,获取生产计划、装车计划、煤质数据等手工录入数据,从自动化系统中获取现场实时数据,对数据进行分析并实时存储,把生产现场的统计数据真实、实时地显示给管理层。该模型可根据原煤质量信息预测不同生产方式下的产品质量,再结合作业成本法在相关系统中对不同生产方式下的产品成本、效益进行统计分析,以效益最大化为原则分析出最优的生产方式组合,为管理层及决策层提供支持。
b)数据标记
数据有预先确定的结果,而未标记数据则没有。如果是标记数据,就会使用有监督机器学习,如:随机森林、逻辑回归或朴素贝叶斯。而未标记的数据需要采用无监督机器学习,如k-means或主成分分析(PCA)。
比如:在实施选煤厂智能密度控制系统模型建立前,或磨机功率优化模型建立前,对大量的原始数据进行主成分分析(PCA),找到对选煤厂重介质悬浮液的密度影响最大的前两项参数,以及对磨机功率影响最大的前两项参数,就极大的减少了后续有监督机器学习的工作量,并加快了现场调试的工作效率。
c)特性的性质
如果你的特征是分类类型的,你可能需要使用决策树或朴素贝叶斯。对于数值特征,线性回归或支持向量机可能更合适。
分类特征:决策树,随机森林,朴素贝叶斯。
数值特征:线性回归,逻辑回归,支持向量机,神经网络, k-means聚类。
混合特征:决策树,随机森林,支持向量机,神经网络。
d) 缺失值
缺失值很多可以使用:决策树,随机森林,k-means聚类。缺失值不对的话可以考虑线性回归,逻辑回归,支持向量机,神经网络。
一些机器学习模型比其他模型更容易解释。如果需要解释模型的结果,可以选择决策树或逻辑回归等模型。如果准确性更关键,那么更复杂的模型,如随机森林或深度学习可能更适合。
如果变量之间可能存在非线性关系,则需要使用更复杂的模型,如神经网络或支持向量机。
低复杂度:线性回归,逻辑回归。
中等复杂度:决策树、随机森林、朴素贝叶斯。
复杂度高:神经网络,支持向量机。
在选矿领域,数据多数属于中、低复杂程度。只有少数选矿流程的智能会采用更高复杂程度的算法。比如:在选煤厂的智能密度控制系统中,以皮带称重、灰分仪器和循环介质密度为输入矩阵,HOT选择神经网络、逻辑回归算法和决策树算法建立数据挖掘模型,进行预测比较,用ROC曲线(Receiver Operating Characteristic)和混淆矩阵进行评估,综合比较后,验证神经网络算法更适合循环介质的预测。此外,在浮选和选矿厂药剂添加系统时,也会用到BP神经网络。


HOT定制化选煤厂智能密度控制系统-大屏界面
如果要考虑速度和准确性之间的权衡,更复杂的模型可能会更慢,但它们也可能提供更高的精度。
速度更重要:决策树、朴素贝叶斯、逻辑回归、k-均值聚类。
精度更重要:神经网络,随机森林,支持向量机。
如果要处理高维数据或有噪声的数据,可能需要使用降维技术(如PCA)或可以处理噪声的模型(如KNN或决策树)。
低噪声:线性回归,逻辑回归。
适度噪声:决策树,随机森林,k-均值聚类。
高噪声:神经网络,支持向量机。
如果需要实时预测,则需要选择决策树或支持向量机这样的模型。
比如:XRT矿物预分拣、XRF矿浆品位检测和预测分析。

如果数据有异常值很多,可以选择像支持向量机或随机森林这样的健壮模型。
对离群值敏感的模型:线性回归、逻辑回归、幂回归。
鲁棒性高的模型:决策树,随机森林,支持向量机。
模型的最终目标就是为了上线部署,所以对于部署难度是最后考虑的因素:
一些简单的模型,如线性回归、支持向量机、决策树等,可以相对容易地部署在生产环境中,因为它们具有较小的模型大小、低复杂度和低运算成本。在大规模、高维度、非线性等复杂数据集上,这些模型的性能可能会受到限制,需要更高级的模型,如神经网络等。
比如:XRT智能预分拣技术的算法,以随机森林、支持向量机等基础算法为主进行矿物和脉石(煤炭和矸石)的识别分析,而不是采用卷积神经网络等算法。因为在XRT的实际生产应用时,需要对矿物进行亚毫秒级的精准分离。更高级的算法,无法满足生产的实际需求。
选择正确的机器学习算法是一项具有挑战性的任务,需要根据具体问题、数据、速度可解释性,部署等都需要做出权衡,并根据需求选择最合适的算法。通过遵循这些指导原则,您可以确保您的机器学习算法非常适合您的特定用例,并可以为您提供所需的见解和预测。






















X
欢迎来到浩沃特!